常见约束
六大约束
- not null:非空,用于保证该字段的值不能为空,比如姓名学号等
- default:默认,用于保证该字段有默认值(性别)
- primary key:主键,用于保证该字段具有唯一性,并且非空,比如学号、员工编号等
- unique:唯一,用于保证字段具有唯一性,可以为空,比如座位号
- check:检查约束【mysql不支持】比如年龄性别
- foreign key:外键,用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联词的值,在从表添加外键约束,用于引用主表中某列的值(比如学生表的专业编号,员工表的部门编号,员工表的工种)
添加约束的时机:
- 创建表时
- 修改表时
约束的添加分类:
列级约束:
六大约束语法上都支持,但外键约束没有效果
表级约束
除了非空、默认,其他的都支持

语法
列级约束
直接在字段名和类型后面追加约束类型即可
只支持:默认、非空、主键、唯一
use students;
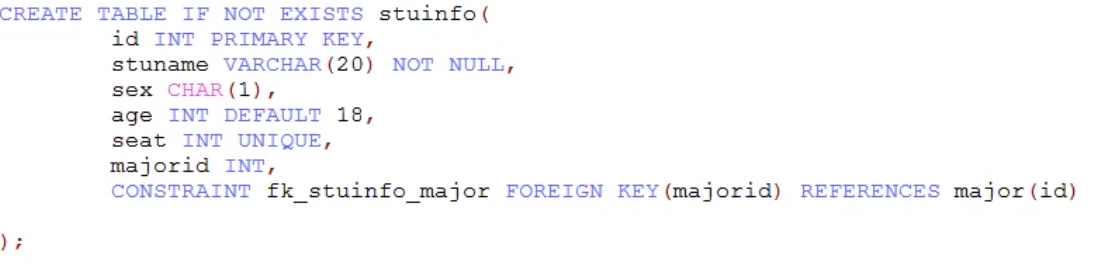
create table stuinfo(
id int primary key,#主键
stuName varchar(20) not null,#非空
gender char(1) check(gender='男' or gender='女'),#检查(mysql中不可用)
seat int unique,#唯一
age int default 18,#默认约束
majorId int references major(id)#外键(mysql中不可用)
)表级约束
在各个字段的最后面
(constraint 约束名) 约束类型(字段名)前面括号内的东西可以不加,有默认的名字
通用的写法
主键和唯一的区别

是否允许组合的意思就是,只有所有内容全部一样才不能执行
外键:
要求从主表设置外键关系
从表的外键列的类型和主表的关联列的类型要求一致或兼容,名称无要求
主表的关联列必须是一个key(一般是主键或唯一)
插入数据时,先插入主表,再插入从表
删除数据时,先删除从表,再删除从表
tip:加约束可以加多个(直接在后面加)
修改表时添加约束
1.添加列级约束
alter table 表名 modify column 字段名 字段类型 新约束
2.添加表级约束
alter table 表名 add [constraint 约束名] 约束类型(字段名)[外键的引用]修改表时删除约束
1.删除非空约束
alter table 表名 modify column 字段名 字段类型 (NULL);
2.删除默认约束(同上)
3.删除主键
alter table 表名 drop primary key;
4.删除唯一
alter table 表名 drop unique;
5.删除外键
alter table 表名 drop foreign key 约束名;
标识列(自增长列)
id int unique auto_increment含义:可以不用手动插入值,系统提供默认的序列值
特点:
- 标识列可以和key搭配(主键,唯一,外键)
- 一个表至多只能有一个标识列
- 标识列的类型只能是数值型
- 标识列可以通过set auto_increment_increment=3 设置步长;可以通过手动插入值,设置起始值。
事务的介绍(TCL语言:事务控制语言)
事务的特性:
ACID


事务的创建

步骤1: 开启事务
set autocommit=0;
start transaction;
步骤2:编写事务中的sql语句(select insert update delete)
语句1;
语句2;
...
步骤3;结束事务
commit;提交事务
rollback;回滚事务
savepoint 节点名;设置保存点rollback回滚事务数据不会变化,只是存储在某一内存中
commit是提交
savepoint例子
set autocommit=0;
start transaction;
delete from account where id=25;
savepoint a;#设置保存点
delete from account where id=28;
rollback to a;#回滚到保存点
结果:id=25 变了,id=28不变事务并发问题的介绍(不是很理解)
数据库的隔离级别

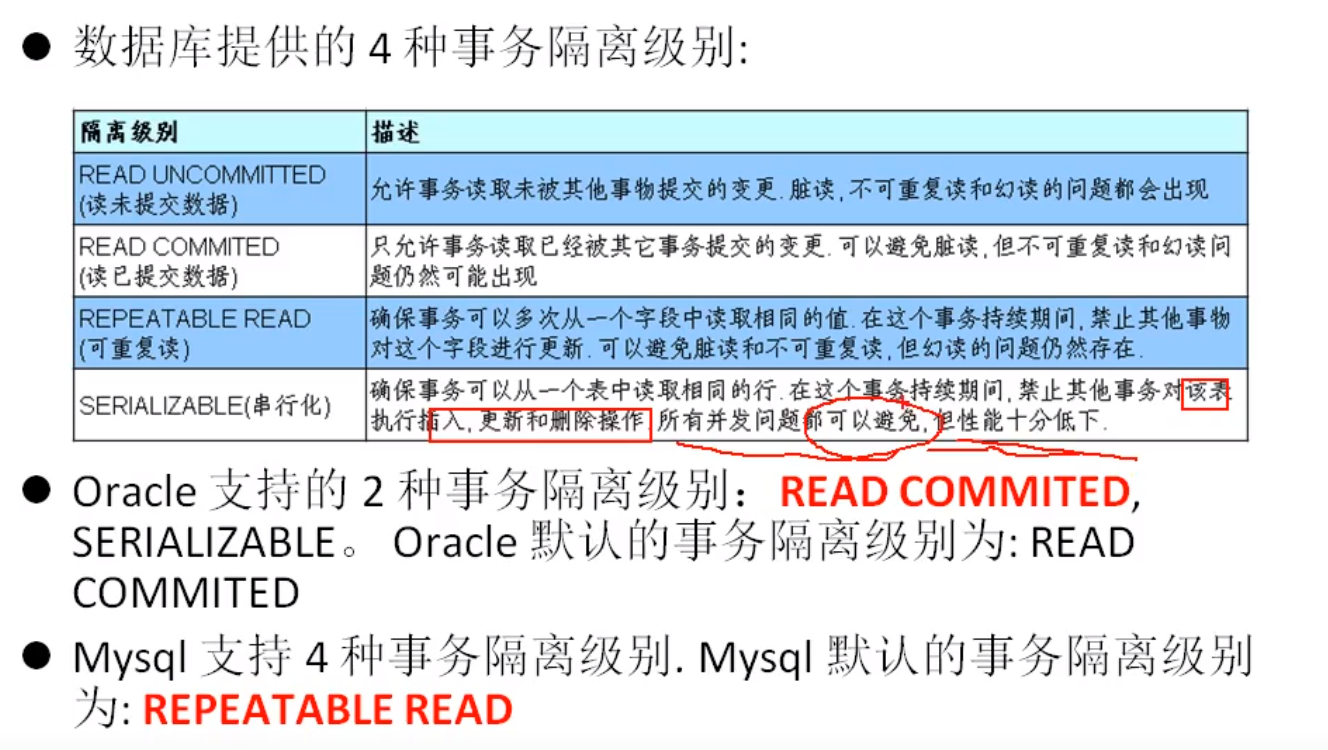

总结:
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| read uncommitted | √ | √ | √ |
| read committed | × | √ | √ |
| repeatable read | × | × | √ |
| serializable | × | × | × |
mysql 中默认第三个隔离级别 repertable read
oracle 中默认第二个隔离级别 read committed
查看隔离级别
select @@tx_isolation;
设置隔离级别
set session | global transaction iso
lation level
视图
视图的介绍
视图:一种虚拟存在的表,行和列的数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的,只保存sql逻辑,不保存查询结果
应用场景:
- 多个地方用到同样的查询结果
- 该查询结果使用的sql语句较复杂
示例:
create view my_v1
as
select studentname,majorname
from student s
inner join major m
on s.majorid=m.majorid
where s.majorid=1;视图的创建
语法:
create view 视图名
as
查询语句;案例:
Q:查询各部门的平均公司级别
#创建视图查看每个部门的平均工资
create view myv2
as
select avg(salary) ag,department_id
from employees
group by department_id;
#使用
select myv2.ag,g.grade_level
from myv2
join job_grades g
onmyv2.ag between g.lowest_sal and g.highest_sal;好处:
- 重用sql语句
- 简化复杂的sql操作,不必知道它的查询细节
- 保护数据,提高安全性
视图的修改
方式1;
create or replace view 视图名
as
查询语句;#修改没有内容就是创建;
alter view myv3
as
查询语句;#修改视图的删除
语法;
drop view 视图名,视图名, ...查看视图
desc 视图名;
show create view 视图名;视图的更新(基本不用)
也有增删改操作,和表的操作一样,可以改变表中的内容

delete 和 truncate在事务使用时的区别
delete 可以回滚,truncate不可以回滚,直接执行删除
变量
系统变量:
- 全局变量
- 会话变量
自定义变量
- 用户变量
- 局部变量
系统变量
使用的语法
查看所有的系统变量
show global|session variables;查看满足条件的部分系统变量
show global|session variables like '%char%';查看指定的某个系统变量的值
select @@global|session.系统变量名为某个系统变量赋值
方式1: set global|session 系统变量名=值; 方式2: set @@global|session.系统变量名=值;注意:如果是全局级别,则需要加global,如果是会话级别,则需要加session,如果不写,则默认session。
改变全局变量可以改变所有,但会话级别只有在当前会话中有效。
全局变量作用域:服务器每次启动将为所有的全局变量附初始值,针对所有的会话(连接)有效,但不能跨重启。
会话变量作用域:仅仅针对于当前会话(连接)有效。
自定义变量
用户变量的作用域:针对当前会话(连接)有效,同于会话变量的作用域。
1.声明并初始化(=或:=)
set @用户变量名:=值;
set @用户变量名=值;
2.赋值
set @用户变量名:=值;
set @用户变量名=值;
或者
select 字段 into @变量名
from 表;
3.使用(查看用户变量的值)
select @用户变量名;局部变量
局部变量作用域:仅仅在定义它的begin end中有效
应用在begin end中的第一句话
1.声明并初始化(=或:=)
declare 变量名 类型;
declare 变量名 类型 default 值;
2.赋值
set 局部变量名:=值;
set 局部变量名=值;
或者
select 字段 into 局部变量名
from 表;
3.使用
select 局部变量名;存储过程和函数

一.创建语法
create procedure 存储过程名(参数列表)
begin
存储过程体(一组合法的sql语句)
end
注意:
1.参数列表包含三部分
参数模式 参数名 参数类型
举例:
in stuname varchar(20)
参数模式:
in:该参数可以作为输入,也就是该该参数需要调用方传入值
out:该参数可以作为输出,也就是该参数可以作为返回值
inout:该参数既可以作为输入又可以作为输出
2.如果存储过程体仅仅只有一句话, begin end可以省略
存储过程体中的每条sql语句的结尾必须要求加上分号
存储过程的结尾可以使用 delimiter 重新设置
语法:
delimiter 结束标记
案例:
delimiter $
二、调用函数
call 存储过程名(实参列表)
空参的存储过程

带in模式的存储过程
案例:创建存储过程实现,用户是否登录成功
create procedure myp4(in nsername varchar(20),in password varchar(20))
begin
declare result int default 0;#声明初始化
select count(*) into result#赋值
from adman
where admin.username=username
andadmin.passward=password;#注意如果名字相同先考虑局部变量
select if(result>0,'成功','失败');#使用
end $带out模式的存储过程
案例:根据女神名,返回对应的男神名和男神魅力值

带inout模式的存储过程
案例:传入a和b两个值,最终a和b都翻倍并返回
create procedure myp8(inout a int, inout b int)
begin
set a=a*2;
set b=b*2;
end $
#调用
set @m=10$
set @n=20$
call myp8(@m,@n)$
select @m,@n$删除存储过程
语法:(一次只能删一个)
drop procedure 存储过程名查看存储过程的信息
语法:
show create procedure 存储过程名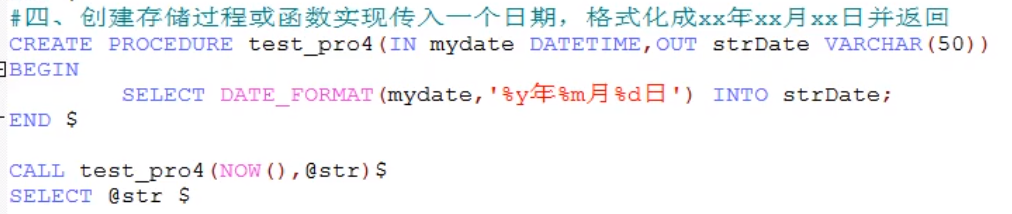
函数的介绍
函数:有且只有一个返回,适合做处理数据后返回一个结果
一:创建语法
create function 函数名(参数列表) returns 返回类型
begin
函数体
end
注意:
参数列表包含两部分
参数名 参数类型
函数体:肯定会有 return 语句,没有也不报错
使用 delimiter 语句设置结束标记
二:调用语法
select 函数名(参数列表)
查看函数
show create function 函数名删除函数
drop function 函数名分支结构——if结构
功能:实现多重分支
if 条件1 then 语句1;
elseif 条件2 then 语句2;
...
end if;
应用在 begin end 中循环结构的介绍
循环结构
分类:
while、loop、repeat
循环控制:
iterate类似 continue,继续,结束本次循环,继续下一次
leave 类似于break,跳出,结束当前循环
如果要加入循环控制,需要给循环加上名字(标签)
- while
{标签:} while 循环条件 do
循环体;
end while {标签};- loop(模拟简单的死循环)
{标签:} loop do
循环体;
end loop {标签};- repeat
{标签:} repeat
循环体;
until 结束循环的条件
end repeat {标签};案例:
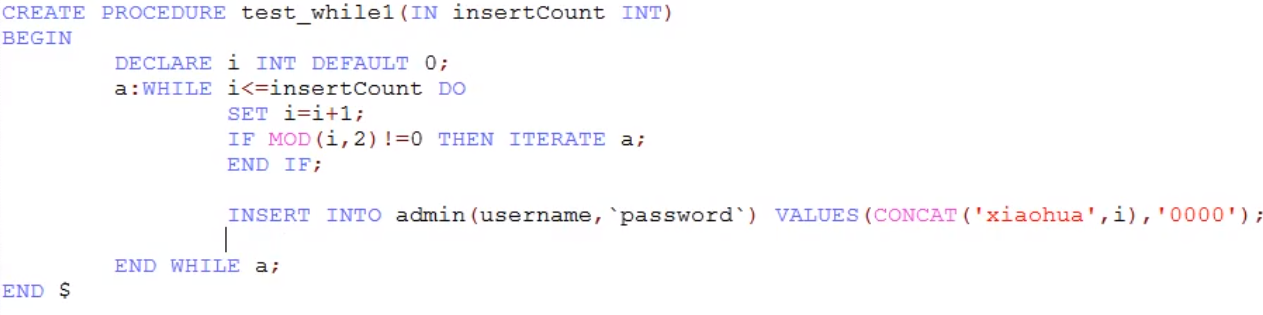
批量插入,根据次数插入到admin表中多条记录,如果次数大于20则停止
create procedure test_while1(in insertCount int)
begin
declare i int default 1;
a: while i=20 then leave a;
end if;
set i=i+1;
end while a;
end $ 案例:批量插入,根据次数插入到admin表中多条记录,只插入偶数次