子查询总结(还需添加p98)
要观察子查询的内容属于(列子查询还是标量子查询)
从而选择(IN,NOT IN….) 还是(=)
其实IN是无敌的
查询平均工资最低的部门信息和该部门的平均工资
select d.*,ag
from (
select avg(salary) ag,department_id
from employees
group by department_id
order by avg(salary)
limit 1
) ag_dep
on d.department_id=ag_dep.department_id联合查询
将多条查询语句的结果合并成一个结果
应用场景:要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时。
语法
查询语句1
union
查询语句2
union
...;案例:查询中国用户中男性的信息以及外国用户中年男性的用户信息
select id,name,csex from t_ca where csex='男'
union
select t_id,tNmae,tGender from t_ua where tGender='male';
注:结尾分号
联合查询的列数必须一致
要求多条查询语句的查询的每一列的类型和顺序最好一致
union关键字是自动去重,union all 可以显示所有
DML语言
插入、修改、删除操作
插入语法
insert into 表名(列1,...)
values(值1,...)注:
插入的值的类型要与列的类型一致或兼容
不可以为null的列必须插入值,可以为null的列如何插入值?
列的顺序可以颠倒,只要值一一对应
列和值的个数必须一致
可以省略列名,默认所有列,而且列的顺序和表中的列的顺序一致
insert into beauty values(18,'张飞','男','119',NULL,NULL)问题2:
- 方式一:插入一个null值
- 方式二:直接在插入时把不写列名
方式二语法
insert into 表名
set 列名=值,列名=值,...方式一支持多行插入,也支持子查询

修改语法
update 表名
set 列名=新值,列名=新值,...
where 筛选条件;案例1:修改beauty表中姓唐的女神的电话为138921837912
update beauty set phone='138921837912'
where name like '唐%';修改多表语法(sql99)
update 表1 别名
inner|left|right join 表2 别名
on 连接条件
set 列=,...
where 筛选条件案例:修改没有男朋友的女神的男朋友编号都为2号
update boys bo
right join beauty on bo.id=b.boyfriend_id
set b.boyfriend_id=2
where bo.id is NULL;删除语句
单表的删除语法
delete from 表名 where 筛选条件多表的删除语法
truncate table 表名(清空数据)或
delete 表1的别名,表2的别名(看要删哪个表自己选)
from 表1 别名
inner|left|right join 表2 别名 on 连接条件
where 筛选条件;案例:删除手机号以9结尾的女神信息
delete from beauty where phone like '%9';
DDL语言
数据定义语言
库与表的管理
库的管理
库的创建
语法(可以加一个判断)
create database [if not exists] 库名库的修改
没有直接的sql语句,可以改文件夹的名字
更改库的字符集
alter database books character set gbk库的删除
drop database [if exists] books表的管理
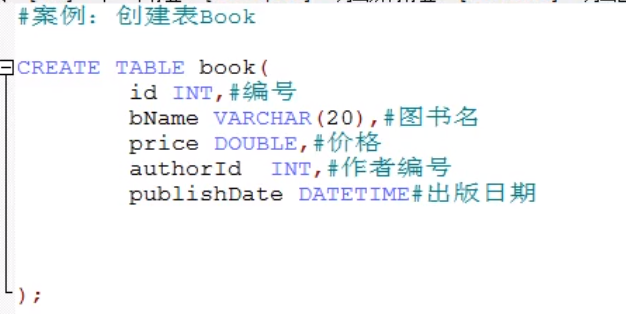
表的创建
create table 表名(
列名 列的类型[(长度) 约束],
列名 列的类型[(长度) 约束],
列名 列的类型[(长度) 约束],
...
列名 列的类型[(长度) 约束]
)
表的修改
alter table 表名 add(加类型)|drop|modify(类型或约束) column 列名 类型 约束alter table 原表名 rename to 新表名alter table 表名 change column 原列名 新列名 类型表的删除
drop table if exists book_author
表的复制
仅仅复制表的结构
create table copy like author复制表的结构+数据
create table copy2
select * from author;只复制部分数据
create table copy3
select id,au_name
from author
where nation='中国';仅仅复制某些字段
create table copy4
select id,au_name
from author
where 0;\表示恒不成立案例(可以跨库复制表结构)

myemmployees.departments,点之前的指的是库名
整形
分类:
tinyint ,smallint,mediumint,(int,integer),bigint特点:
- 如果不设置无符号还是有符号,默认是有符号,如果想设置无符号,需要添加unsigned关键字
- 如果插入的数值超出了整形的范围,会报out of range异常,插入的值就是临界值
- 如果不设置长度,会有默认的长度(显示结果的宽度)zerofill关键字可以用于填充0,填充到设置的宽度为止
浮点型
分类
浮点型
float(M,D)
double(M,D)
定点型
dec(M,D)
decimal(M,D)特点:
- M:整数部分+小数部分
- D:小数部分
如果超过输出临界值
M,D都可以省略
如果是decimal,则M默认是10,D默认是0
如果是float和double,则会根据插入的数值的精度来决定精度
定点数精度较高
字符型
较短的文本(最大的字符数)
char(M)
varchar(M)
较长的文本:
text
blob
枚举插入(不在括号内的不行
大小写都可以,但输出都是小写)
enum('a','b','c')
set('a','b','c','d')
set使用
 结果:
结果:
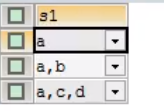
日期型


datetime 和timestamp 的区别




